Currently, there is no agreed-upon malware naming convention among AV companies. Although this is not for the lack of trying as there are multiple "standards", ranging from Caro to Microsoft.

When you find some malware in the wild, sometimes you want to find the procedure to remove that malware or at least, given it is some known malware, figure out what properties it has.
Let's do an example: Here is a random malware found on Virustotal. Different AVs give it different names and a person unfamiliar with typical nomenclature may not know what any of them mean. Also, most AVs don't agree on a naming convention, which makes interpreting the results difficult. Moreover, we are not sure which results are correct and what they correspond to.
Running the sample through peframe we get a little more information:
Short information
------------------------------------------------------------
File Name 33d781c7ca3745870451d8a3d2ade10689005dc9f6070cc78e5ad594bdb54936
File Size 5632 byte
Compile Time 2007-12-25 08:15:18
DLL No
Sections 1
Hash MD5 61c9ddb015db820cbdb8a2f39548b7a1
Hash SAH1 3a5a79982e72fe2210a0722b0cea3d35520c2441
Imphash 87bed5a7cba00c7e1f4015f1bdae2183
Packer Yes
Anti Debug No
Anti VM No
Directory Import
Packer matched [1]
------------------------------------------------------------
Packer kkrunchy 0.23 alpha 2 -> Ryd
Suspicious API discovered [2]
------------------------------------------------------------
Function GetProcAddress
Function LoadLibraryA
File name discovered [1]
------------------------------------------------------------
Library KERNEL32.DLL
So "krunchy" is a packer that obfuscates the code.
And after running it through the Cuckoo Sandbox we see that this malware seems to modify the hosts file:
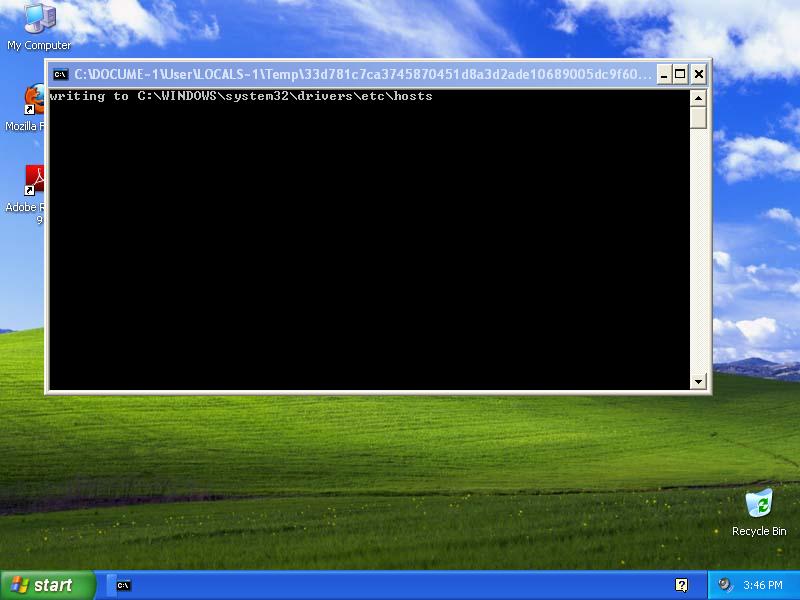
So both Qhost and Krunchy are relatively correct names for the "family" of the malware, although Qhost is probably better.
We are not going to try to come up with a new standard, but instead settle on a decent name for the malware. One way to do that is to use the names given by the AV vendors.
Using Tf-idf
The various naming conventions can include a lot of information such as unique id and the platform it runs on or the language it uses. This is not particularly useful because it reaveals little information about what the malware does and how to get rid of it. Additionally, the platform/language can be inferred using filemagic, while a unique identifier might as well be a fuzzy hash of the file.
So how do we extract the family name? We could use a simple statistical strategy called Term Frequency x Inverse Document Frequency or tf-idf. It works by counting the number of times each word occurs in a document and multiplying it by the log of number of documents over number of documents that have that word. That is,
Here, \(t\) is the term, \(d\) is one document, \(D\) is all documents, \(N\) is the number of documents.
First we scan a bunch of malware on VT, make a file called "50kresults.json" with 50k antivirus results in the following format:
[{"AV1": "Win32.Malware.name", "AV2": "Trojan.horse"}, {"AV1": "Win32.BadVirus", "AV2": "JS.Iframe"}]
To figure out the family based on tf-idf we can do the following:
import json
import re
from sklearn.feature_extraction.text import TfidfVectorizer
def get_list_of_token_lists(list_of_dicts):
"""Convert [{"AV": "Some.Malware"}, {"AV":"Another.Malware"}] => [["Some", "Malware"], ["Another", "Malware"]]"""
big_list = []
for _dict in list_of_dicts:
inner_list = []
for v in _dict.values():
if v is not None:
inner_list.extend([x for x in re.split("\W", v) if x])
big_list.append(inner_list)
return big_list
def make_tfidf(list_of_dicts):
tfidf = TfidfVectorizer(analyzer=lambda x: x)
tfidf.fit(get_list_of_token_lists(list_of_dicts))
return tfidf
j = json.load(open("50kresults.json"))
# our result for the Qhost/Krunchy malware
d = {'TrendMicro': 'TROJ_QHOST.GO',
'Comodo': 'TrojWare.Win32.Trojan.Inject.~INC',
'Avast': 'Win32:QHost-BMV',
'VIPRE': 'Packed.Win32.Krunchy',
'Fortinet': 'W32/Krunchy.A!tr',
'Ikarus': 'Packer.Krunchy.B',
'AhnLab-V3': 'Win-Trojan/Krunchy.91147',
'F-Secure': 'DeepScan:Generic.Malware.Qw.CEE83C79',
'VBA32': 'suspected',
'DrWeb': 'Trojan.DownLoader.31981',
'Jiangmin': 'Trojan/Qhost.adx',
'Panda': 'Trj/CI.A',
'BitDefender': 'DeepScan:Generic.Malware.Qw.CEE83C79',
'GData': 'DeepScan:Generic.Malware.Qw.CEE83C79',
'Kaspersky': 'Trojan.Win32.Qhost.aed',
'nProtect': 'Trojan/W32.Qhost.5632',
'Norman': 'W32/Packed_Krunchy.A',
'McAfee': 'Generic',
'Symantec': 'Trojan.SpamThru',
'K7AntiVirus': 'Trojan',
'Sophos': 'Mal/Generic-L',
'TrendMicro-HouseCall': 'TROJ_QHOST.GO',
'Antiy-AVL': 'Trojan/Win32.Qhost.gen',
'PCTools': 'Trojan.SpamThru',
'AVG': 'Obfustat.ADPJ',
'ViRobot': 'Spyware.Delf.Do.5632.A',
'Avast5': 'Win32:QHost-BMV',
'Microsoft': 'Trojan:Win32/Meredrop',
'CAT-QuickHeal': 'Trojan.Qhost.aed',
'NOD32': 'probably',
'McAfee-GW-Edition': 'Heuristic.LooksLike.Win32.Suspicious.F!83',
'VirusBuster': 'Trojan.Qhost.GQ',
'Emsisoft': 'Packer.Krunchy.B!IK',
'AntiVir': 'TR/Crypt.XPACK.Gen',
'Commtouch': 'W32/Trojan2.THU',
'F-Prot': 'W32/Trojan2.THU'}
j.append(d)
tfidf = make_tfidf(j)
to_guess = d
print("We have to guess the family name in the following result:\n")
print(to_guess)
l_of_l = get_list_of_token_lists([to_guess])
m = tfidf.transform(l_of_l)
els_to_pos = {e: tfidf.vocabulary_[e] for e in l_of_l[0]}
els_to_scores = {k: m[:, v].toarray()[0][0] for k, v in els_to_pos.items()}
print("\nTop 3 results for families:")
print(sorted([(token, score) for (token, score) in els_to_scores.items() if len(token) > 3], key=lambda x: x[1], reverse=True)[:3])
And we get the following output:
Top 3 results for families:
[('Krunchy', 0.45202206291544067), ('Qhost', 0.38232102610232943), ('CEE83C79', 0.28923118570941675)]
So this worked pretty well.
However, this strategy does not always work. For example, for the following set of results:
{'Comodo': 'UnclassifiedMalware',
'Avast': 'Win32:Dropper-gen',
'VIPRE': 'Trojan.Win32.Generic!BT',
'Fortinet': 'W32/Small.JGG!tr.dldr',
'Agnitum': 'Trojan.PWS.Nilage!7qzxMXSt8xA',
'AhnLab-V3': 'Trojan/Win32.Downloader',
'F-Secure': 'Trojan.Generic.4486012',
'DrWeb': 'Trojan.DownLoader1.14982',
'Jiangmin': 'Trojan/PSW.Nilage.eeb',
'Panda': 'Trj/CI.A',
'BitDefender': 'Trojan.Generic.4486012',
'GData': 'Trojan.Generic.4486012',
'Kaspersky': 'Trojan-GameThief.Win32.Nilage.hjm',
'nProtect': 'Trojan/W32.Small.23040.AU',
'VBA32': 'TrojanPSW.Nilage',
'McAfee': 'PWS-Lineage!l',
'Symantec': 'Spyware.Keylogger',
'K7AntiVirus': 'Riskware',
'Antiy-AVL': 'Trojan/win32.agent.gen',
'PCTools': 'Spyware.Keylogger!rem',
'AVG': 'PSW.OnlineGames3.APII',
'TheHacker': 'Trojan/Nilage.hjm',
'Ikarus': 'Trojan-Downloader.Win32.Banload',
'ESET-NOD32': 'a',
'McAfee-GW-Edition': 'PWS-Lineage!l',
'NANO-Antivirus': 'Trojan.Win32.Nilage.bcufrb',
'Emsisoft': 'Trojan.Generic.4486012',
'AntiVir': 'TR/Crypt.CFI.Gen',
'MicroWorld-eScan': 'Trojan.Generic.4486012',
'Commtouch': 'W32/Risk.ZZEX-7195',
'Norman': 'Downloader',
'K7GW': 'Password-Stealer',
'F-Prot': 'W32/MalwareF.IIVH'}
The process yields:
Top 3 results for families:
[('4486012', 0.53745997540319712), ('Nilage', 0.53215845680514295), ('Trojan', 0.18195861475064623)]
Where Trojan and the 4486012 number result are not what we are interested in.
Using CRF
So how do we figure out which If we re-frame the problem of figuring out a good name into the problem of labeling parts of virus names and then combining the labels from different antiviruses, we can see it as a text segmentation problem.
In our case, text segmentation can be used to infer what each part of a virus name means. That is,
"Win32.Agent.1234"
Can be split into
["Win32", "Agent", "1234"]
and labeled as
["Platform", "Family", "id"]
After that, based on all the platform names that we get from AVs we can figure out what the consensus is. We want to use CRFs instead of something like Naive Bayes, because the order of tokens within each AV’s name for a virus is very important and because the tokens are not independent (i.e. An Iframe family malware is probably written in Javascript).
There are a number of algorithms that can be used to infer what each part of the virus name means including those based on Hidden Markov Models (HMM) and Conditional Random Fields (CRF). There is already an excellent explanation of how HMMs work and how to figure out what the states are on the Viterbi Algorithm Wiki.
CRFs can be viewed as a generalization of HMMs that makes the constant transition probabilities such as from Healthy to Fever on the wiki page into arbitrary functions that vary across the positions in the sequence of hidden states (Health or Fever), depending on the input sequence (normal, cold or dizzy).
Here we will use the excellent CRFSuite library to label the states. We’ll create some training data, convert it to features, train a model and run it on some results we haven’t seen before.
First, let’s create some training data to label parts of virus names with their corresponding tags. We would want to convert antivirus results such as
[{"AntiVir": "TR/Crypt.XPACK.Gen2"}, {"AntiVir":"DR/Delphi.Gen"}]
into the following:
TR 0 AntiVir _type
/ / AntiVir delim
Crypt 1 AntiVir family
. . AntiVir delim
XPACK 2 AntiVir group
. . AntiVir delim
Gen2 3 AntiVir ident
DR 0 AntiVir _type
/ / AntiVir delim
Delphi 1 AntiVir family
. . AntiVir delim
Gen 2 AntiVir ident
With the last column being the labels that will later be guessed. To create the above format, we can use the following:
import itertools
import re
REGEX_NONWORD = re.compile("\W")
REGEX_NONWORD_SAVED = re.compile("(\W)")
def preprocess_av_result(av_result, av):
"""Split an av result into a list of maps for word, pos, av and label
EG. take something like 'win32.malware.group' and convert to
[{'av': 'someav', 'w': 'win32', 'pos': '0', 'label': 'skip'},
{'av': 'someav', 'w': '.', 'pos': '.', 'label': 'delim'},
{'av': 'someav', 'w': 'malware', 'pos': '1', 'label': 'skip'},
{'av': 'someav', 'w': '.', 'pos': '.', 'label': 'delim'},
{'av': 'someav', 'w': 'group', 'pos': '2', 'label': 'skip'}]
"""
split_delim = [el if el != ' ' else '_' for el in
REGEX_NONWORD_SAVED.split(av_result)]
split_no_delim = REGEX_NONWORD.split(av_result)
delims = set(split_delim) - set(split_no_delim)
counter = 0
tags = []
labels = []
for el in split_delim:
if el in delims:
labels.append('delim')
tags.append(el)
else:
labels.append('skip')
tags.append(str(counter))
counter += 1
return [{'w': i, 'pos': j, 'av': k, 'label': l} for i, j, k, l in
zip(split_delim, tags, itertools.repeat(av), labels) if i != '']
j = json.load(open("50kresults.json"))[:1000] # contains the results
with open("all_train.txt", 'w') as f: # name of the training file
for d in j:
for av, res in d.items():
if res is None:
continue
features = preprocess_av_result(res, av)
for fd in features:
f.write('\t'.join([fd['w'], fd['pos'], fd['av'], fd['label']]) + "\n")
f.write("\n")
After creating and manually labeling the tokens (we label the last column in “all_train.txt” according to what we think the token actually corresponds to), we want to create a feature file that crfsuite understands. To convert the result to features, we can use the slightly modified script built into crfsuite called ‘chunking.py’ that converts labeled CSV file to feature file. All we have to do to take advantage of the fact that CRF can use the fact that each antivirus uses a slightly different naming convention is to modify the template (included below).
templates = (
(('w', -2), ),
(('w', -1), ),
(('w', 0), ),
(('w', 1), ),
(('w', 2), ),
(('w', -1), ('w', 0)),
(('w', 0), ('w', 1)),
(('pos', -2), ),
(('pos', -1), ),
(('pos', 0), ),
(('pos', 1), ),
(('pos', 2), ),
(('pos', -2), ('pos', -1)),
(('pos', -1), ('pos', 0)),
(('pos', 0), ('pos', 1)),
(('pos', 1), ('pos', 2)),
(('pos', -2), ('pos', -1), ('pos', 0)),
(('pos', -1), ('pos', 0), ('pos', 1)),
(('pos', 0), ('pos', 1), ('pos', 2)),
(('av', 0), ),
)
We save it to chunking_av.py and run it with the following command:
cat all_train.txt | ./chunking_av.py > all_train.crfsuit.txt
After that, we have to train the model using the features file:
crfsuite learn -m all_train.model all_train.crfsuit.txt
After that, we can check how the model performs with some testing data:
cat all_test.txt | ./chunking_av.py > all_test.crfsuite.txt
crfsuite tag -m all_train.model -t all_test.crfsuite.txt
Annnnd….
Performance by label (#match, #model, #ref) (precision, recall, F1):
_type: (80, 80, 80) (1.0000, 1.0000, 1.0000)
delim: (558, 558, 558) (1.0000, 1.0000, 1.0000)
family: (159, 162, 159) (0.9815, 1.0000, 0.9907)
group: (19, 19, 19) (1.0000, 1.0000, 1.0000)
ident: (152, 152, 156) (1.0000, 0.9744, 0.9870)
skip: (95, 97, 95) (0.9794, 1.0000, 0.9896)
platform: (109, 109, 112) (1.0000, 0.9732, 0.9864)
language: (12, 15, 13) (0.8000, 0.9231, 0.8571)
method: (7, 7, 7) (1.0000, 1.0000, 1.0000)
compiler: (0, 0, 0) (******, ******, ******)
_test: (0, 0, 0) (******, ******, ******)
malic: (27, 27, 27) (1.0000, 1.0000, 1.0000)
Macro-average precision, recall, F1: (0.697204, 0.705046, 0.700773)
Item accuracy: 1218 / 1226 (0.9935)
Instance accuracy: 152 / 160 (0.9500)
We are primarily interested in the family accuracy which is at ~98%. Good enough.
Now we can use the “all_train.model” file to tag tokens in new malware names. First, create a function for extracting features from labeled text:
def extract_features(X):
all_features = []
for i, _ in enumerate(X):
el_features = [X[i]['label']]
for template in templates:
features_i = []
name = '|'.join(['%s[%d]' % (f, o) for f, o in template])
for field, offset in template:
p = i + offset
if p < 0 or p >= len(X):
features_i = []
break
features_i.append(X[p][field])
if features_i:
el_features.append('%s=%s' % (name, '|'.join(features_i)))
all_features.append(el_features)
all_features[0].append('__BOS__')
all_features[-1].append('__EOS__')
return all_features
Then use the Tagger class from python-crfsuite library to label the malware:
from pycrfsuite import Tagger
tagger = Tagger()
tagger.open("all_train.model") # our model file we created in previous step.
k, v = 'F-Prot', 'W32/LoadMoney.K.gen!Eldorado' # av result from previous section
result = tagger.tag(extract_features(preprocess_av_result(v, k)))
print("Antivirus:", k)
print("Antivirus result:", v)
print("Tokenized result:", [res['w'] for res in preprocess_av_result(v, k)])
print("Labeled result", result)
We get the following output:
Antivirus: F-Prot
Antivirus result: W32/LoadMoney.K.gen!Eldorado
Tokenized result: ['W32', '/', 'LoadMoney', '.', 'K', '.', 'gen', '!', 'Eldorado']
Labeled result ['platform', 'delim', 'family', 'delim', 'ident', 'delim', 'skip', 'delim', 'ident']
It worked! We now know what each token corresponds to. We can further improve results by modifying the template, including additional features, do further post-processing such as picking one name among synonymous names, grouping similarly spelled labels, etc.
But this seems to be good enough for now.
Once we have all the post-processing in place, we can even guess the labels of the malware we could't get with Tf-idf:
In [1]: import name_generator
In [2]: g = name_generator.Guesser()
In [3]: d = {'Comodo': 'UnclassifiedMalware',
'Avast': 'Win32:Dropper-gen',
'VIPRE': 'Trojan.Win32.Generic!BT',
'Fortinet': 'W32/Small.JGG!tr.dldr',
'Agnitum': 'Trojan.PWS.Nilage!7qzxMXSt8xA',
'AhnLab-V3': 'Trojan/Win32.Downloader',
'F-Secure': 'Trojan.Generic.4486012',
'DrWeb': 'Trojan.DownLoader1.14982',
'Jiangmin': 'Trojan/PSW.Nilage.eeb',
'Panda': 'Trj/CI.A',
'BitDefender': 'Trojan.Generic.4486012',
'GData': 'Trojan.Generic.4486012',
'Kaspersky': 'Trojan-GameThief.Win32.Nilage.hjm',
'nProtect': 'Trojan/W32.Small.23040.AU',
'VBA32': 'TrojanPSW.Nilage',
'McAfee': 'PWS-Lineage!l',
'Symantec': 'Spyware.Keylogger',
'K7AntiVirus': 'Riskware',
'Antiy-AVL': 'Trojan/win32.agent.gen',
'PCTools': 'Spyware.Keylogger!rem',
'AVG': 'PSW.OnlineGames3.APII',
'TheHacker': 'Trojan/Nilage.hjm',
'Ikarus': 'Trojan-Downloader.Win32.Banload',
'ESET-NOD32': 'a',
'McAfee-GW-Edition': 'PWS-Lineage!l',
'NANO-Antivirus': 'Trojan.Win32.Nilage.bcufrb',
'Emsisoft': 'Trojan.Generic.4486012',
'AntiVir': 'TR/Crypt.CFI.Gen',
'MicroWorld-eScan': 'Trojan.Generic.4486012',
'Commtouch': 'W32/Risk.ZZEX-7195',
'Norman': 'Downloader',
'K7GW': 'Password-Stealer',
'F-Prot': 'W32/MalwareF.IIVH'}
In [4]: g.guess_everything(d)
Out[4]:
{'family': 'Nilage',
'platform': 'Win32',
'group': 'unknown',
'ident': 'hjm',
'language': 'unknown',
'compiler': 'unknown',
'_type': 'Trojan'}
All of the post-processing to settle on one common name has already been done and you can find the library that can guess the virus names at this github repo.